Новейшая графическая архитектура Maxwell для разработчиков
Недавно состоялась невероятно волнующая презентация в индустрии GPU-вычислений — анонс графических процессоров известного производителя NVIDIA на новой архитектуре первого поколения под названием Maxwell. Одни из первых продукты на представленной архитектуре Maxwell, а именно GeForce GTX 750 Ti, основаны на новейшем чипе GM107. Их предназначение — использование во всевозможных портативных устройствах. Ключевой же момент Maxwell, который относится к разработчикам HPC и ряда других GPU-приложений — это невероятно большой скачок в энергетической эффективности — почти в 2 раза по сравнению с архитектурой Kepler. Улучшение этой и еще ряда характеристик делает архитектуру Maxwell замечательной базой для продуктов ближайшего будущего, которые относятся к в линейке NVIDIA Tesla.
В этой статье вы сможете ознакомится с главными вещами, которые касаются архитектуры Maxwell и необходимы любому разработчику GPU-приложений: преимуществах архитектуры, специфике памяти и нового потокового процессора и многом другом.
Высокоффективные мультипроцессоры — сердце Maxwell
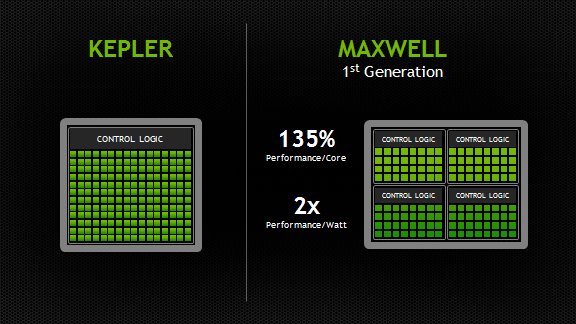
Потоковый процессор (далее SM) в Maxwell называют SMM. Данный тип процессора создан с нуля. Его основное преимущество — значительно большая энергетическая эффективность по сравнению со всеми его предшественниками. Стоит отметить, что потоковый процессор Kepler SMX — это достаточно эффективный для своего поколения процессор, ведь в результате его создания разработчики и инженеры NVIDIA увидели совершенно новые возможности в плане повышении эффективности всей архитектуры GPU, которые и были успешно реализованы в линейке SM Maxwell. Основные улучшения затронули механизмы распределения нагрузки и управляющей логики, гранулярности всех алгоритмов энергосбережения, планирования и количества исполняемых за такт инструкций разного рода, а также ряда других аспектов, которые позволили SM Maxwell значительно опередить Kepler SMX по практически всем параметрам. Новейшая архитектура SM Maxwell позволила разработчикам увеличить количество SM до 5 в модели GM107 (это на 3 больше, чем в модели GK107), при этом площадь матрицы увеличилась всего на 25%.
Улучшенное планирование всех инструкций

Стоит отметить, что в одном SM количество ядер CUDA сократилось, но с учетом того, что эффективность исполнения в Maxwell намного возросла (прирост производительности в перерасчете на SM — около 10% от производительности Kepler) и размеры SM стали более эффективны, общее количество ядер CUDA на GPU станет намного больше, чем у Kepler и Fermi. В Maxwell SM оставили такое же количество всех планировщиков инструкций, при этом значительно уменьшились задержки на любого рода арифметических операциях в сравнении с Kepler.
Любой SMM, как и SMX, обладает 4-мя warp-планировщиками, но в отличие от SMX, в SMM абсолютно все функциональные ключевые блоки привязаны к определенным планировщикам, а не распределяются между ними. Количество ядер в одном разделе теперь равно степени двойки, что значительно упрощает планирование, ведь каждый планировщик теперь использует исключительно свой собственный набор ядер с количеством, которое равно непосредственно размеру warp`а. Каждый warp-планировщик способен, как и раньше, за 1 такт выполнять 2 инструкции, например, выполняя операции обращения к памяти в блоке load/store одновременно математической операцией на CUDA-ядрах. Стоит отметить, что теперь есть возможность полностью загрузить все CUDA-ядра даже в том случае, если планировщик отправляет на выполнение только по 1-ой инструкции.
Увеличенная скорость загрузки потоковых процессоров
SMM многими аспектами своей архитектуры похож на SMX с архитектурой Kepler, при этом основные изменения нового типа процессоров были направлены на значительное повышение эффективности без необходимости сильно увеличивать параллелизм при расчете на SM в любом приложении. Так, остались прежними:
- размер регистрового файла — 64K для 32-битных регистров;
- максимальное количество warp`ов на SM — 64 штук;
- максимальное количество регистров — 255 штук.
Максимальное же количество блоков на каждый потоковый мультипроцессор SMM удвоилось и составляет теперь 32 штуки. Это несомненно должно привести к автоматическому увеличению максимальной загрузки для всех ядер, использующих небольшой размер блока — 64 или меньше. Также разделяемая память и регистры не ограничивают загрузку мультипроцессора.
Уменьшение задержки в процессе выполнении арифметических инструкций
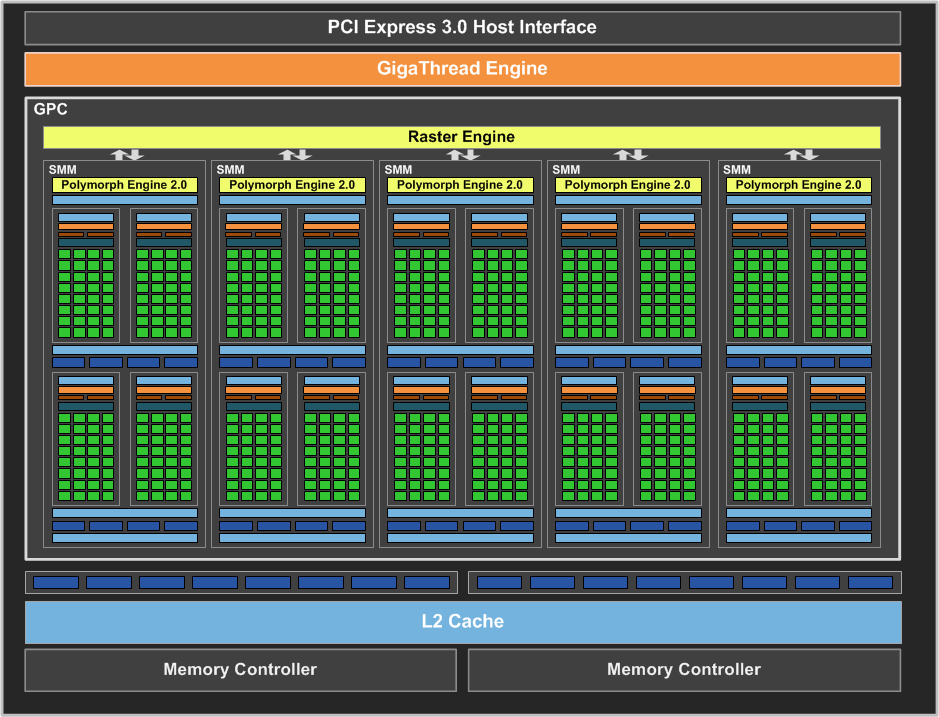
Еще одно значительное преимущество SMM — это уменьшение задержек при выполнении любых арифметических инструкций. Поскольку загрузка мультипроцессора (которая способна преобразовываться в параллелизм на warp-уровне) у SMM лучше, чем у SMX, то значительно сокращенные задержки намного улучшают использование CUDA-ядер а также повышают непосредственно скорость работы самого ядра.
В таблице ниже представлены сравнительные ключевые характеристики Maxwell GM107 и Kepler GK107.
|
GPU |
GK107 (Kepler) |
GM107 (Maxwell) |
|
Ядра CUDA |
384 |
640 |
|
Boost-частота GPU |
н/д |
1085 МГц |
|
Базовая частота |
1058 МГц |
1020 МГц |
|
GFLOPs |
812,5 |
1305,6 |
|
Разделяемая память / SM |
16 Кб / 48 Кб 3,0 |
64 Кб |
|
Compute Capability |
3,0 |
5,0 |
|
Размер регистрового файла / SM |
256 Кб |
256 Кб |
|
Частота памяти |
5000 МГц |
5400 МГц |
|
Максимальное количество блоков / SM |
16 |
32 |
|
Полоса пропускания памяти |
80 Гб/с |
86,4 Гб/с |
|
TDP |
64 Вт |
60 Вт |
|
Размер кэша L2 |
256 Кб |
2048 Кб |
|
Транзисторы |
1,3 млрд. |
1,87 млрд. |
|
Техпроцесс |
28 нм |
28 нм |
|
Площадь кристалла |
118 мм2 |
148 мм2 |
Выделенная общая память значительно увеличена
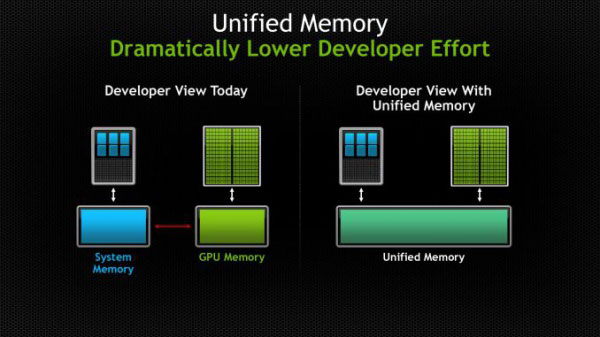
В архитектуре Maxwell разработчики предусмотрели 64 Кбайт специально разделяемой памяти (в Fermi или Kepler такая память распределяется между L1 — кэшем первого уровня — и разделяемой памятью). В архитектуре Maxwell 1 блок, как и раньше, может использовать до 48 Кб разделяемой памяти, при этом значительное увеличение общего объема всей разделяемой памяти, как правило, приводит к увеличению загрузки всего мультипроцессора. Такие показатели стали возможны благодаря объединению всего функционала кэша L1 с текстурным кэшем непосредственно в отдельном блоке.
Скоростные атомарные операции в разделяемой памяти
Новые встроенные атомарные операции в архитектуре Maxwell, которые производятся над 32-битными целыми числами в вышеупомянутой разделяемой памяти, CAS-операции над 64-битными и 32-битными значениями также разделяемой памяти — это существенная помощь в реализации целого ряда других атомарных функций. В процессе использования Kepler и Fermi было необходимо применение достаточно сложного принципа под названием «Lock/Update/Unlock», что конечно же приводило к ряду существенных дополнительных издержек.
Динамический параллелизм
Динамический параллелизм, который появился еще в Kepler GK110, позволяет GPU создавать задачи самому для себя. Поддержка данной функции впервые была добавлена еще в CUDA 5.0, позволяя запускать дополнительные виртуальные ядра на том же самом GPU.
На сегодняшний день поддержка динамического параллелизма присутствует абсолютно во всех продуктах изготовителя, включая даже достаточно экономичные чипы, такие как GM107. Создателям и разработчикам это выгодно, поскольку теперь для разного рода приложений нет необходимости в создании специальных алгоритмов, использующихся в последних новейших GPU и отличающихся от тех, которые до сих пор используются в графических процессорах существенно низшего уровня.
Просмотреть подробные сведения об оптимизации кода и архитектуре под Maxwell можно на оффициальном сайте https://developer.nvidia.com/user/login, где эта и много другой интересной информации уже доступны для зарегистрированных разработчиков CUDA.








